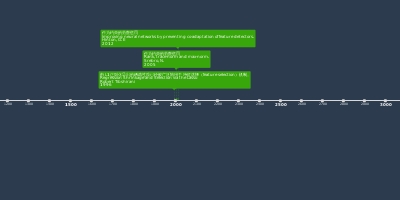
10 сент 2019 г. - 针对推导迁移学习的正则化 使用论文里提出的 L2-SP 代替 L2 惩罚 A baseline regularization scheme for transfer learning with convolutional neural networks Xuhong Li, Yves Grandvalet, Franck Davoine 2019.9
Описание:
文中指出 fine-tuning 可能会导致本来已学到的知识丢失。Добавлено на ленту времени:
Дата:
10 сент 2019 г.
Сейчас
~ 6 г назад