Quantization timeline
Category: Outro
Atualizado: 29 mar 2020
The quantization development history
Autores

Created by龚成
Attachments

Eventos
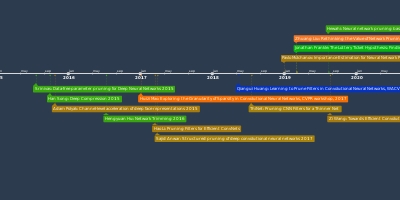
Han Song:
Deep compression: Compressing deep
neural networks with pruning, trained
quantization and huffman coding, 2015M Courbariaux:
Binarized neural networks:
Training deep neural networks
with weights and activations
constrained to+ 1 or-1 (BNNs)Ternary Weight
Networks (TWNs)Trained Ternary
Quantization (TTQ)Training and Inference
with Integers in Deep
Neural NetworksHAQ: Hardware-Aware
Automated Quantization
With Mixed Precision, CVPR, 2019Extremely Low Bit Neural
Network Squeeze the Last
Bit Out with ADMM, AAAI, 2018Dorefa-Net: training
low-bitwidth CNN with
low-bitwidth gradientsCLIP-Q: Deep Network
Compression Learning
by In-Parallel Pruning-
Quantization (CVPR 2018)Ternary Neural Networks
for Resource-Efficient AI
Applications (TNNs)Philipp Gysel:
Hardware-oriented Approximation
of Convolutional Neural NetworksCanran Jin:
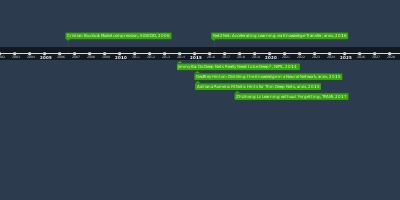
Sparse Ternary Connect:
Convolutional Neural Networks
Using Ternarized Weights
with Enhanced Sparsity (STC)ChengGong:
$\mu$L2Q: An Ultra-Low Loss
Quantization Method for DNNBichen Wu:
Mixed precision quantization
of convnets via differentiable
neural architecture search, 2018Lei Deng:
GXNOR-Net: Training deep neural
networks with ternary weights and
activations without full-precision
memory under a unified discretization
framework, NN, 2018Rastegari:
XNOR-Net: Imagenet classification
using binary convolutional neural
networks, ECCV, 2016Deep Learning with Low
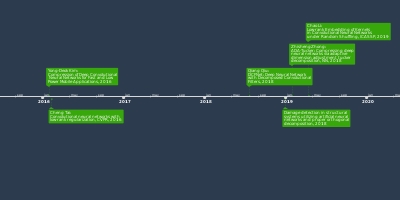
Precision by Half-wave
Gaussian Quantization (HWGQ)Deep Neural Network
Compression with Single and
Multiple Level QuantizationTwo-Step Quantization for
Low-bit Neural Networks,
CVPR, 2018Incremental Network Quantization:
Towards Lossless CNNs with Low-
Precision Weights, INQ, 2017Yao Chen:
T-DLA: An Open-source Deep
Learning Accelerator for Ternarized
DNN Models on Embedded FPGA, 2019Daisuke Miyashita:
Convolutional Neural Networks using
Logarithmic Data RepresentationForward and Backward Information Retention
for Accurate Binary Neural Networks, CVPR 2020Retrain-Less Weight Quantization for
Multiplier-Less Convolutional Neural NetworksImproving Neural Network Quantization without
Retraining using Outlier Channel Splitting, arxiv“Binaryconnect: Training deep neural networks
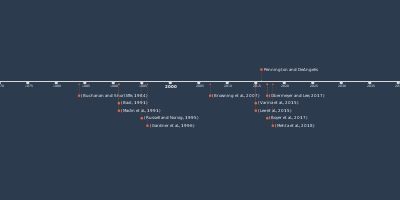
with binary weights during propagations, NIPSNeural networks with few multiplicationsQAT: Quantization and training of neural
networks for efficient integer-arithmetic-only
inference, CVPR
Comments